Predicting BJJ Competitions - Part 1 Gathering Data
In the modern era, data is readily available online if you can leverage your creativity, web scraping, and data wrangling skills to find it. In this post, I demonstrate how to scrape the internet to create a dataset focused on my favorite hobby, jiu jitsu. The website BJJHeroes provides records of wins and losses for BJJ athletes at major tournaments. These win/loss records offer an exciting dataset for building a prediction model, a classic data science problem.
The pen may be mightier than the sword, but in another, much more real way, it isn't.
Delve into the Data
From the moment I sparred in jiu jitsu, I was hooked. As a smart, geeky kid, I always fantasized about being able to defend myself using intelligence rather than strength or agility. The idea that one can use intellect to defend oneself is based on the commitment to learning the necessary principles. Beyond being great exercise and an incredible social environment, the jiu jitsu mats offer intense mental stimulation that significantly enhances your confidence and character.

After six years of intense study and countless hours of sparring, Brazilian Jiu Jitsu remains my favorite hobby. I think about it constantly, so why not use this passion as a portfolio project to showcase my data science skills? Ideally, I would explore a dataset that could help me improve my craft. Just as I benefit from studying instructional videos, I hope to refine my skills through data analysis. In this series of posts, I aim to explore available jiu jitsu data online and assemble a dataset to study and enhance my jiu jitsu.
To start our data exploration process, we need to assemble a dataset. The website BJJHeroes provides easily accessible data on win and loss records for major jiu jitsu competitions. In the section below, I use the Python library BeautifulSoup to scrape this data and compile it into a single pandas DataFrame.
The web scraping process appears relatively simple because of the way the BJJHeroes website is set up. The navigation bar has a
heroes list
link that provides a table with all of the fighters' first and last names. Furthermore, the fight history data that I am interested in is organized on their webpage with the following URL structure:
https://www.bjjheroes.com/bjj-fighters/"first-name-last-name". We can therefore easily scrape the data from the heroes list table, concatenate the last and first names together with a hyphen, and then iterate through the names to access the win/loss data for each fighter. In the image below, you can see an example of the fight history table that we intend to scrape for one of my favorite BJJ practitioners, Lachlan Giles, at
bjjheroes.com/bjj-fighters/lachlan-giles.
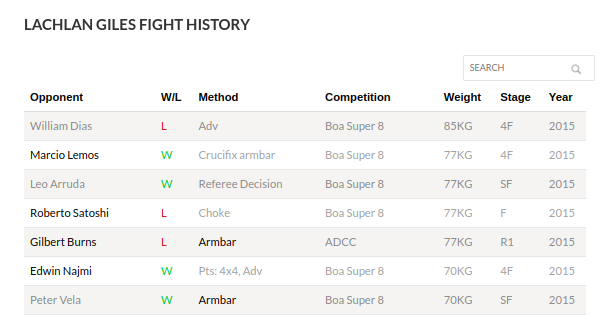
The Python code below scrapes the table containing fighters' first and last names. I use the `requests` library to access the web URL and then utilize Beautiful Soup to parse the HTML, collecting all elements with the table row ('< tr >') tag. The data is compiled into a nested list, with each athlete's First Name, Last Name, Nickname, and Team. This nested list is then converted into a pandas DataFrame.
Scrape the Fighter Name Table
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL to scrape
url = 'https://www.bjjheroes.com/a-z-bjj-fighters-list'
# Fetch the URL content
response = requests.get(url)
response.raise_for_status() # Ensure the request was successful
# Parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Find the desired table
table = soup.find('table', {'id': 'tablepress-8'})
# Extract table headers
headers = [header.text for header in table.find_all('th')]
# Extract table rows
rows = table.find_all('tr')[1:] # Skip the header row
# Extract data from each row
data = []
for row in rows:
cols = row.find_all('td')
cols = [col.text.strip() for col in cols]
data.append(cols)
# Create a DataFrame
fighters = pd.DataFrame(data, columns=headers)
fighters['Full Name Lower'] = fighters['First Name'].str.lower() + '-' + fighters['Last Name'].str.lower()
print(fighters.head())
| First Name | Last Name | Nickname | Team | Full Name Lower |
|---|---|---|---|---|
| Aarae | Alexander | N/A | Team Lloyd Irvin | aarae-alexander |
| Aaron | Johnson | Tex | Unity JJ | aaron-johnson |
| Abdurakhman | Bilarov | N/A | Team Nogueira | abdurakhman-bilarov |
| Abmar | Barbosa | N/A | N/A | abmar-barbosa |
| Abraham | Marte Messina | N/A | Yamasaki / Basico | abraham-marte messina |
The assembled dataset seems to be exactly what we need to initiate the scraping process. The table from BJJHeroes was successfully scraped, and we added a column that combines the fighter's first and last names with a hyphen—mirroring the URL pattern used on the website containing the fighter record data. This column can then be used as an iterator in a loop to scrape the fighter record table we are interested in.
Now that we can easily access the "Full Name Lower" iterator, we can proceed to scrape the fight record table from each individual athlete's page. The scraping process closely mirrors the previously detailed method, with the primary difference being that it occurs within a `for` loop to dynamically match the URL pattern for each fighter.
The first step involves defining the web domain prefix stored in the `web_prefix` variable, which serves as the base URL for constructing the athlete-specific URLs. We then initialize a list called `scraped_data` to store the extracted data for each fighter. The "Full Name Lower" column from the fighters dataset is selected to use as the iterator for the loop.
For each name in the "Full Name Lower" list, we construct the URL of the corresponding fighter's page and send an HTTP GET request to retrieve the page's HTML content. We check the response status code to ensure successful retrieval. If the retrieval is unsuccessful, we log the failure and continue to the next name. Once the HTML content is retrieved successfully, we parse it using BeautifulSoup to locate the `div` with the class `table-responsive`.
If the `div` is found, we search for the `table` element within it and then iterate over its rows, skipping the header row. For each row, we extract the relevant columns (represented by `td` elements) and store the data in the `scraped_data` list. If the `table` or `div` is not found, we log an appropriate message indicating the issue.
After completing the iterations and scraping the necessary data, we convert the `scraped_data` list into a Pandas DataFrame. Finally, we save the DataFrame to a CSV file named `win_loss_scraped.csv`. This method ensures that we have a detailed dataset compiled from each athlete's page, which can be used for subsequent analysis.
Scrape the Fighter Record Tables Using the Fighter's Names
## Web domain prefix
web_prefix = 'https://www.bjjheroes.com/bjj-fighters/'
# List to store data
scraped_data = []
### Take the names for testing
names = fighters['Full Name Lower']
# Loop through each name in 'Full Name Lower' and scrape data
for name in names:
url = f"{web_prefix}{name}"
print(f"Scraping data from: {url}")
response = requests.get(url)
if response.status_code != 200:
print(f"Failed to retrieve {url} with status code {response.status_code}")
continue
soup = BeautifulSoup(response.text, 'html.parser')
table_div = soup.find('div', class_='table-responsive')
if table_div:
table = table_div.find('table')
if table:
rows = table.find_all('tr')
for row in rows[1:]: # Skip the header row
cols = row.find_all('td')
if len(cols) > 0:
scraped_row = {
'Name': name,
'Opponent': cols[1].text.strip(),
'W/L': cols[2].text.strip(),
'Method': cols[3].text.strip(),
'Competition': cols[4].text.strip(),
'Weight': cols[5].text.strip(),
'Stage': cols[6].text.strip(),
'Year': cols[7].text.strip()
}
scraped_data.append(scraped_row)
else:
print(f"No table found for {name}")
else:
print(f"No 'table-responsive' div found for {name}")
# Convert list of scraped data to a DataFrame
scraped_df = pd.DataFrame(scraped_data)
scraped_rename = scraped_df.rename(columns={'Full Name Lower':'URL Tag'})
scraped_rename.to_csv('win_loss_scraped.csv', index=False)
Now that our dataset is assembled correctly, I need a tool to quickly review my data to understand it better. In this example, I will use the `ydata_profiling` package, which takes a Pandas DataFrame and returns a concise HTML report summarizing the data.
Review the Fighter Record Table
import pandas as pd
from ydata_profiling import ProfileReport
# Load your dataset
df = pd.read_csv('win_loss_scrape.csv')
# Generate a profile report
profile = ProfileReport(df, title="YData Profiling Report", explorative=True)
# Save the report to an HTML file
profile.to_file('ydata_profile_report.html')
View ydata Fighter Record Summary
The `ydata_profiling` package contains an excellent tool for data summarization. It provides quick visualizations for each data type in the DataFrame, along with other useful features such as the number of missing elements. An example of the URL tag we used for the iterator in web scraping is shown below.
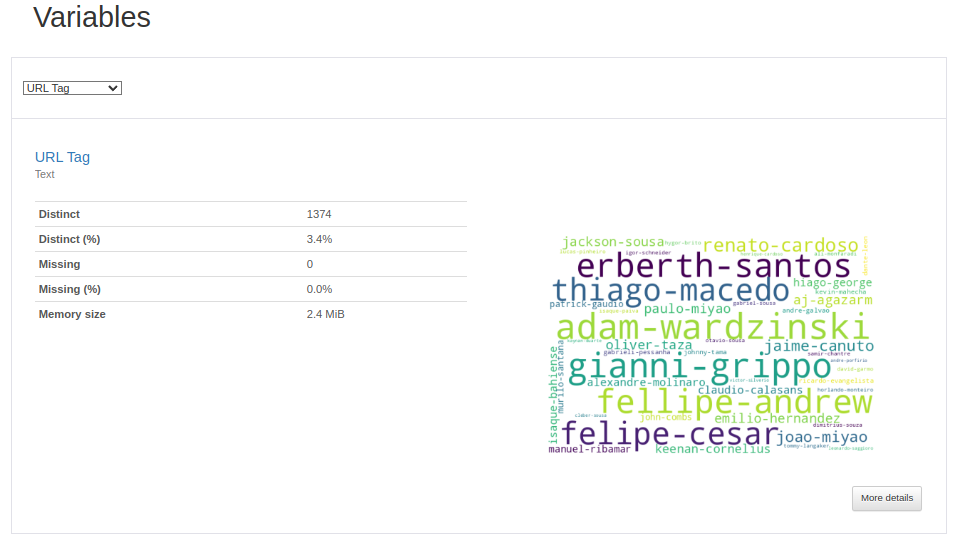
Scanning through this data immediately reveals a comprehensive to-do list of issues that need to be addressed. I will highlight these issues in the sections below and return to fix them as I progress further into the data preparation process. Some of the issues are as follows:
- There is missing data in most columns except for the URL pattern. This is likely due to fighters' pages that didn't successfully scrape the win-loss table.
- The dataset contains significantly more wins than losses. This likely indicates that pages of unsuccessful fighters have been removed.
- The weight classes are represented by strings and not treated as ordinal factors.
- There appear to be duplicate rows in the dataset.
Before I address these data issues, I want to gain a better understanding of the dataset. While the overall dataset appears to be exactly what I am looking for, what will happen if I ask a simple question, such as: Who are the best BJJ fighters based on their win rate
Which Fighters Have the Highest Win Percentage
import pandas as pd
# Read the CSV file into a DataFrame
record = pd.read_csv('bjj_win_loss.csv')
# Remove any leading/trailing whitespace from column names
record.columns = record.columns.str.strip()
# Group by 'Name' and aggregate the 'W/L' column
record_agg = record.groupby('Name')['W/L'].value_counts().unstack(fill_value=0).reset_index()
# Rename columns for clarity
record_agg = record_agg.rename(columns={'W': 'Wins', 'L': 'Losses', 'N/A': 'Not Applicable'})
# Ensure all necessary columns are present
for col in ['Wins', 'Losses', 'Not Applicable']:
if col not in record_agg.columns:
record_agg[col] = 0
# Create new column with win percentage
# eval method saves rewriting record_agg for each column
record_agg['Win Rate'] = record_agg.eval('Wins / (Wins + Losses)')
# filter the dataframe to remove people with high win rates but not a lot of fights
filtered_record = record_agg[record_agg['Wins'] > 40]
selected_record = filtered_record[['Name', 'Wins', 'Losses', 'Win Rate']]
# Display the top 10 fighters with highest win percentage with more than 40 wins on their record
print(selected_record.sort_values(by ='Win Rate', ascending=False).head(10))
| Name | Wins | Losses | Win Rate |
|---|---|---|---|
| gabrieli-pessanha | 174 | 6 | 0.966667 |
| tainan-dalpra | 81 | 3 | 0.964286 |
| gordon-ryan | 100 | 5 | 0.952381 |
| andrew-tackett | 35 | 2 | 0.945946 |
| micael-galvao | 96 | 6 | 0.941176 |
| erich-munis | 89 | 6 | 0.936842 |
| meyram-maquine | 104 | 9 | 0.920354 |
| roger-gracie | 76 | 7 | 0.915663 |
| julia-alves | 79 | 8 | 0.908046 |
| marcus-almeida | 138 | 14 | 0.907895 |
The table above is largely what I was looking for. We have columns showing the wins, losses, and win percentage for each of the URLs that I scraped. While everything appears as expected, I am surprised to see only a couple of prominent names at the top of the list. I expected to see Gordon Ryan and Roger Gracie, who are widely considered the greatest no-gi and gi grapplers, respectively. However, many other notable figures are missing. For instance, I expected to see Mikey Musumeci among the men and Gabi Garcia among the women. When I filter the dataset to specifically find these grapplers, I notice that these athletes don't exist in my dataset.
Reviewing the URL scraping, I notice that the `michael-musumeci` URL tag should actually use the nickname column from our data to be `mikey-musumeci`. Additionally, for Gabi Garcia, the URL tag mistakenly has an extra "-bjj" appended to the end. I now realize that I need to adjust the URL patterns after performing some basic data manipulation with Pandas to construct the iterator for referencing the URLs as desired.
In the next section of code, I will concatenate the fighter nickname along with the last name and see how many additional entries to the fighter record dataframe I have complied. The code for the scraping is identical to that shown in the scraping section above, however, the pandas columns used as the iterator for the scraping for loop will be changed as shown below.
Dealing with Nicknames
## Create a New Column that is a hypenated lower case nickname-last-name
fighters['Hyphenated Names'] = fighters['Last Name'].apply(lambda x: x.replace(' ', '-') if ' ' in x else x).str.lower()
fighters['Nickname Ref'] = fighters['Nickname'].str.lower() + '-' + fighters['Hyphenated Names'].str.lower()
## Filter to only scrape fighters with nicknames.
## nickname_df['Nickname Ref'] will be the iterator
nickname_df = fighters[~fighters['Nickname Ref'].str.startswith('-')]
The scraped nickname data contains the tournament record for 15 fighters including fighters of interest like Mikey Musumeci, Jay Rodriguez, Xande Ribeiro, etc.
Similarly, the code below shows how I create the iterator for the scraping the fighters with multi-part last names.
Dealing with Multi-Part Last Names
## Create a column to with the spaces replaced with a hyphen
fighters['Hyphenated Names'] = fighters['Last Name'].apply(lambda x: x.replace(' ', '-') if ' ' in x else x).str.lower()
fighters['Multi'] = fighters['First Name'].str.lower() + '-' + fighters['Hyphenated Names']
## Filter the dataframe we only scrape fighters that had a space in their last name
multipart_df = fighters[fighters['Last Name'].str.contains(' ')]
Scraping for the names that are multi part adds an additional 19 fighters to my dataset.
Finally, to address the fighters with "-bjj" attached at the of their name in the web url, I repeat the same process, by concatenating "-bjj" to the end of the iterator as shown in the code below.
Scraping Fighters with the -bjj suffix
fighters['Multi'] = fighters['First Name'].str.lower() + '-' + fighters['Hyphenated Names'] + '-bjj'
Scraping the url pattern with attaching "-bjj" to the end of the fighter's names allows me to add 10 fighters to this list. While I'm not sure if it was intentional, but several very famous fighters ended up having "-bjj" at the end of the url including, Andre Galvalo, Rafael Mendes, Renzo Gracie, etc.
Now that I have these three extra groups of fighters to add to my win/loss dataframe, I will import three .csv files I saved for each scraping group and connect the dataframes together with the fighter record data I was using earlier. Now that I have a more complete record, I will use the url patterns from the complied fighter record dataframe when I scrape the other data that I was interested in.
Scraping Fighters with the -bjj suffix
import pandas as pd
## Import the nickname and multiname records
nickname_df = pd.read_csv('nickname_records.csv')
multi_df = pd.read_csv('multiname_records.csv')
suffix_df = pd.read_csv('bjj_suffix.csv')
# ## Import the original dataframe
original_df = pd.read_csv('bjj_win_loss.csv')
original = original_df.drop(columns=['First Name', 'Last Name', 'Nickname', 'Team'])
final_df = pd.concat([nickname_df, multi_df, suffix_df, original], ignore_index= True)
final = final_df.drop(columns=[ 'Full Name Lower'])
final.to_csv('full_athlete_list.csv')
I can now use the column 'Name' from the saved full_athlete_list.csv as the iterator for future scraping loops with some simple data manipulation. The next step is to scrape the remaining data I am interested in, specifically, the website views, the main achievements, and the biography. This is achieved in the section of code below.
This is accomplished in a similar way to the scrape above. I import the complete win/loss data frame that I have assembled and take the unique athlete url patterns and place it into a second dataframe. I create a new column with the url patterns I want to scrape to use as the iterator in my scraping for loop.
The views count I wanted to to scrape is easily accessible as it is found within a unique span class called "meta-info-viewer". The view count is dispayed as a string in a format like this: 16.65K. This number is then converted to a number and stored in a list for storage
The biography and other valuable text information is stored in a div section with the "text-content" class. All of the text stored in p-tags within this section scraped using a for loop and assembled into a list.
A second dataframe is assembled using the athlete Names, View Number and Biography and then saved as a .csv file for later use. I considered connecting both datasets into one large dataframe, but didn't elect to do so because there would have been a large amount of repetition in the biography category. If I intend to pull predictive features out of the biography, I would like to have a dataset without repetition.
Scraping the Views and Biography
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Load the CSV file
win_record_df = pd.read_csv('full_athlete_list.csv')
# Base URL for constructing URL patterns
base_url = 'https://www.bjjheroes.com/a-z-bjj-fighters-list'
# Get unique athlete names
athelete_names = win_record_df['Name'].unique()
# Create a new DataFrame with unique athlete names
athelete_df = pd.DataFrame(athelete_names, columns=['Name'])
# Create a new column for URL patterns
athelete_df['Url Pattern'] = base_url + '/' + athelete_df['Name']
# Filter out the rows where 'Url Pattern' is NaN
athelete_df = athelete_df.dropna(subset=['Url Pattern'])
# Limit the list of URLs to scrape (for example, the first 5)
urls = athelete_df['Url Pattern']
names = athelete_df['Name']
# Function to extract the text content from all tags within a given tag
def extract_text_from_p_tags(parent_tag):
paragraphs = parent_tag.find_all('p')
biography = ""
for paragraph in paragraphs:
biography += paragraph.get_text() + " "
return biography.strip()
# List to hold the scraped data
data = []
# Iterate through each URL and corresponding athlete name in the list
for name, url in zip(names, urls):
# Send a GET request to the webpage
response = requests.get(url)
# Parse the HTML content with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Find the span element with class 'meta-info-viewer'
span_element = soup.find('span', class_='meta-info-viewer')
# Initialize the number variable
number = None
# Extract the text content from the span element
if span_element:
text = span_element.text.strip()
print("Extracted text:", text)
# Remove the 'K' suffix and convert to a number
if 'K' in text:
number = float(text.replace('K', '')) * 1000
else:
number = float(text) # If the number doesn't have 'K', just convert it directly
# Convert the number to an integer
number = int(number)
print("Converted number:", number)
else:
print("Span element with class 'meta-info-viewer' not found.")
# Find the
with class 'text-content'
text_content_div = soup.find('div', class_='text-content')
# Extract biography information
print("Biography Information:")
biography = extract_text_from_p_tags(text_content_div)
print(biography)
# Append the scraped data to the list along with the athlete's name
data.append([name, number, biography])
# Create a DataFrame from the scraped data
scraped_df = pd.DataFrame(data, columns=['Name', 'Number', 'Biography'])
# Combine the scraped data with the original athlete DataFrame
final_df = pd.merge(athelete_df, scraped_df, on='Name', how='left')
# Save the final DataFrame to a CSV file
final_df.to_csv("second_scrape.csv", index=False)
The two datasets can be downloaded using the links below.
Download fighter_record.csv
Download fighter_profile.csv
In the upcoming entry of this series, I will apply fundamental data science techniques to develop a predictive model aimed at forecasting the winners of the forthcoming ADCC event. While this analysis is intended for recreational purposes, constructing a model capable of predicting binary outcomes can have significant applications in a professional context. For instance, such a model could be employed to predict customer churn or to generate odds for a bookmaker wagering on sports events like this one.
Tags
Predicting ADCC Part 2: Building a Model